Kubernetes Kubernetes Homelab Series (Part 3): Monitoring and Observability with Prometheus and Grafana Welcome back to the Kubernetes Homelab Series! 🚀 In the previous post, we set up persistent storage with Longhorn and MinIO. Today, we’re enhancing our cluster with a full monitoring Pablo del Arco 27 feb. 2025 · 4 min de lectura
Kubernetes Kubernetes Homelab Series (Part 2): Longhorn + MinIO for Persistent Storage Welcome back to the Kubernetes Homelab Series! After building a strong foundation in Part 1 with a two-node Kubernetes cluster, it’s time to take our homelab to the next Pablo del Arco 16 ene. 2025 · 6 min de lectura
Kubernetes Kubernetes Homelab Series (Part 1): How I Built My Kubernetes Cluster from Scratch This is my first post, and I couldn’t be more excited to share this journey with you! I’ve always been amazed by cloud and virtualization technologies, so I Pablo del Arco 8 ene. 2025 · 4 min de lectura
OpenNebula Conference Last week, OpenNebula Community celebrated the 11th edition of the OpenNebula Conference. You can watch all the sessions on demand on their website or YouTube channel, where you can find Jordi Guijarro 2 jul. 2024 · 1 min de lectura
Backup Copias de seguridad con Kopia Kopia: herramienta de respaldo moderna y rápida para usuarios, con soporte para diferentes repositorios, deduplicación eficiente y compresión opcional. Protege tus datos de forma segura. Aitor Roma 2 jun. 2023 · 3 min de lectura
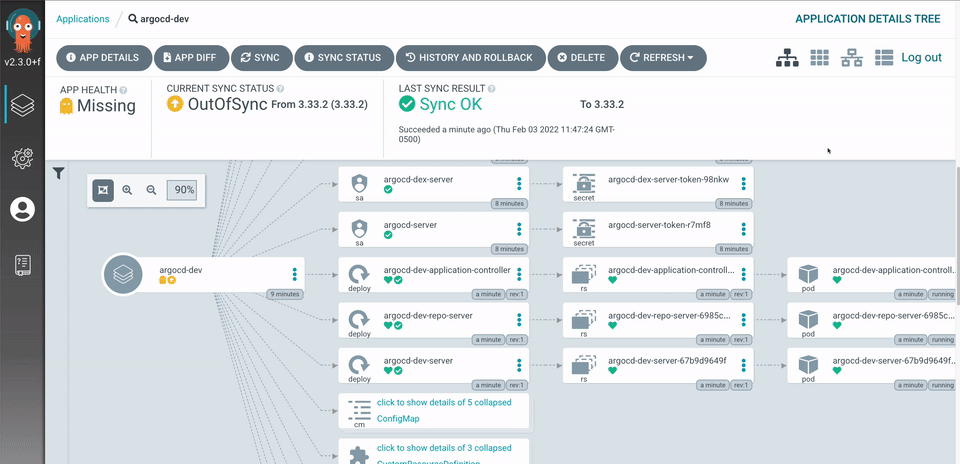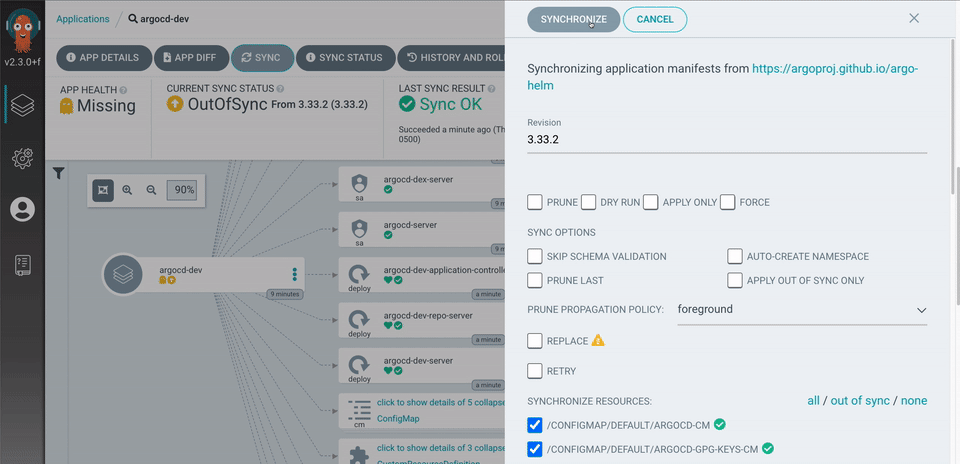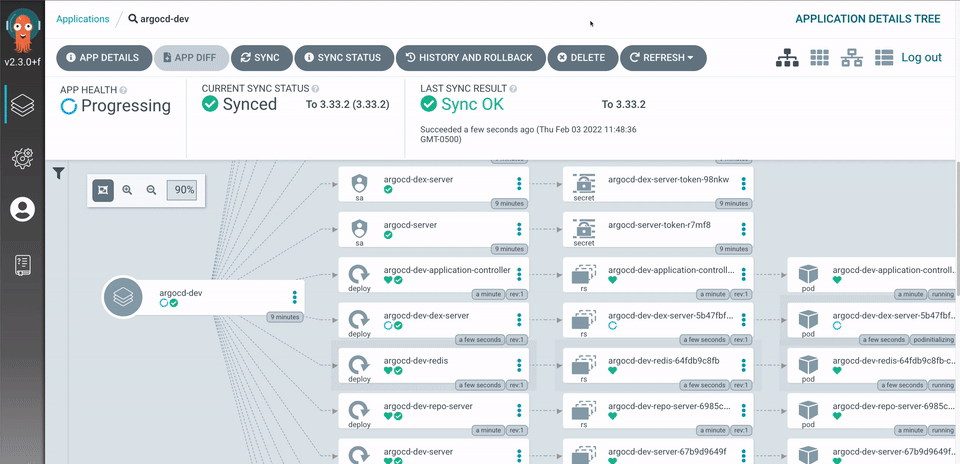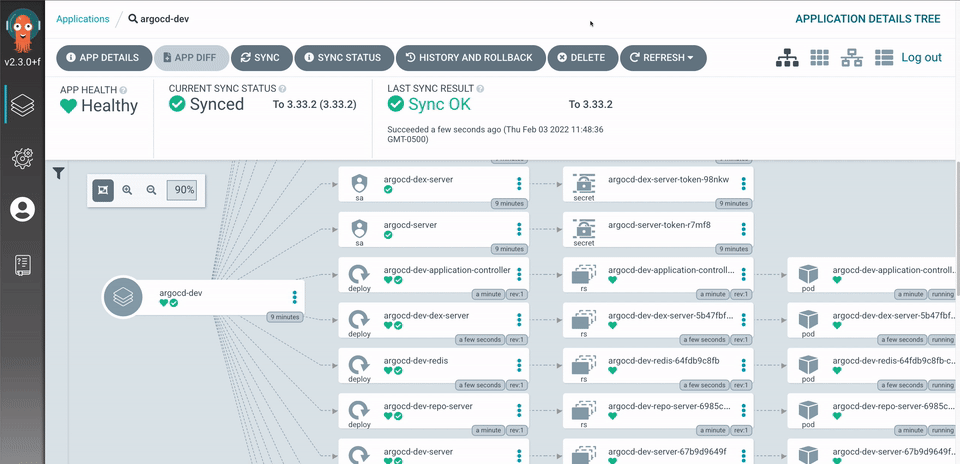
Argo Vault Plugin (AVP) Installation via HELM Introduction One of the most important questions when it comes to dealing with GitOps is knowing where to store your secrets and how to manage them securely. Some of the Alex Vaqué 1 jun. 2023 · 10 min de lectura
AI4CYBER : AI aplicada a ciberseguridad ¡El siguiente Meetup de Barcelona Cybersecurity & Cloudadmins Barcelona ya está aquí! Registro aquí https://www.meetup.com/cloud-admins-barcelona/events/293260777/ i2CAT nos abre sus oficinas (Carrer del Gran Capità, Jordi Guijarro 1 may. 2023 · 2 min de lectura
Cloud Security Baseline tooling to secure a small environment with SECaaS SECaaS experience from the PALANTIR R&D project. The article briefly introduces part of the associated cloud-native tooling to provide a security baseline to a small environment. Carolina Fernández 13 dic. 2022 · 3 min de lectura
🚀🚀 GitOps TechDay Barcelona 30/11/22 18h CEST The Cloudadmins TechDays are educational and networking events organized by Cloudadmins.org and local partners/sponsors. Join our technical experts and the local Cloudadmins Community, learn about relevant use cases, Jordi Guijarro 5 nov. 2022 · 2 min de lectura
CfP - OpenNebulaCon 2022 It’s great to attend the OpenNebulaCon, this year taking place online from May 31 – June 2, 2022, yet being a speaker… is even better! 🤓 Come share your insights and Jordi Guijarro 27 mar. 2022 · 1 min de lectura
Herramientas útiles para la administración de un cluster de Kubernetes Kubernetes es a día de hoy el orquestador de contenedores open-source más usado y es por ello que han ido apareciendo un gran número de herramientas con las que gestionar Marius Duch 24 ene. 2022 · 2 min de lectura
Recording 🚀🚀 Cyberops e-TechDay Barcelona 24/11/21 16h CEST The Cloudadmins TechDays (now turned virtual due to the COVID-19 pandemic) are educational and networking events organized by Cloudadmins.org and local partners/sponsors. Join our technical experts and the Jordi Guijarro 1 dic. 2021 · 1 min de lectura
🚀🚀 Cyberops e-TechDay Barcelona 24/11/21 16h CEST Details The Cloudadmins TechDays (now turned virtual due to the COVID-19 pandemic) are educational and networking events organized by Cloudadmins.org and local partners/sponsors. Join our technical experts and Jordi Guijarro 2 nov. 2021 · 1 min de lectura
Recording 🚀🚀 Workflow Automation e-TechDay Barcelona (#cybersecurity #sre) Details The Cloudadmins TechDays (now turned virtual due to the COVID-19 pandemic) are educational and networking events organized by Cloudadmins.org and local partners/sponsors. Join our technical experts and Jordi Guijarro 29 sep. 2021 · 2 min de lectura
🚀e-TechDay OpenNebula Cloud 2021 28/9 15:00h About this e-TechDay The OpenNebula TechDays (now turned virtual due to the COVID-19 pandemic) are educational and networking events organized by OpenNebula user groups and local partners. Join our technical Miguel Ángel Flores 15 sep. 2021 · 2 min de lectura
🚀🚀 Workflow Automation e-TechDay Barcelona 15/9/21 19h CEST Details The Cloudadmins TechDays (now turned virtual due to the COVID-19 pandemic) are educational and networking events organized by Cloudadmins.org and local partners/sponsors. Join our technical experts and Jordi Guijarro 30 ago. 2021 · 2 min de lectura
Teletrabajo Àlex trabaja como ingeniero de sistemas desde Móra d'Ebre Entrevista a Àlex Vaque, un CloudAdmin al que el Teletrabajo le ha permitido volver al pueblo donde creció. Alex Vaqué 20 ago. 2021 · 3 min de lectura
Building Europe’s Digital Sovereignty: the role of open source, edge computing and GAIA-X event, was a total success The event focused on discussing with several experts the role that open source, edge computing, and GAIA-X are expected to play in the process of building Europe’s digital sovereignty, Jordi Guijarro 12 jul. 2021 · 2 min de lectura
 Kubernetes
Kubernetes